| Tweet |
|
Topik:
|
Apa Itu BERT?Oleh: Hobon.id (16/02/2026)
 BERT adalah singkatan dari Bidirectional Encoder Representations from Transformers. Ini adalah model deep learning yang diperkenalkan pada tahun 2018 oleh para peneliti di Google yang secara signifikan meningkatkan cara mesin memahami bahasa manusia. BERT adalah singkatan dari Bidirectional Encoder Representations from Transformers. Ini adalah model deep learning yang diperkenalkan pada tahun 2018 oleh para peneliti di Google yang secara signifikan meningkatkan cara mesin memahami bahasa manusia.BERT didasarkan pada arsitektur Transformer dan dirancang untuk menangkap konteks kata dalam kalimat dengan lebih baik. Tidak seperti model bahasa sebelumnya yang memproses teks dalam satu arah—baik dari kiri ke kanan atau dari kanan ke kiri—BERT menganalisis teks secara dua arah. Ini berarti ia melihat kata-kata yang mendahului dan mengikuti kata tertentu, sehingga memungkinkan pemahaman kontekstual yang lebih dalam. Rilis BERT menandai tonggak penting dalam natural language processing (NLP) dan membentuk kembali cara kerja mesin pencari, chatbot, dan model bahasa. Advertisement:
Mengapa BERT Merupakan RevolusionerSebelum BERT, banyak model NLP kesulitan memahami konteks, terutama ketika makna suatu kata sangat bergantung pada kata-kata di sekitarnya. Misalnya, perhatikan kata "bank" dalam kalimat-kalimat berikut: "She deposited money at the bank." "He sat by the river bank." Model tradisional sering menafsirkan kata-kata secara terpisah atau dengan konteks yang terbatas. Namun, BERT menganalisis seluruh kalimat sekaligus, sehingga mampu membedakan berbagai makna berdasarkan konteks. Pemahaman dua arah ini memungkinkan BERT mencapai kinerja terbaik pada berbagai tolok ukur NLP, termasuk menjawab pertanyaan, klasifikasi kalimat, dan tugas inferensi bahasa. 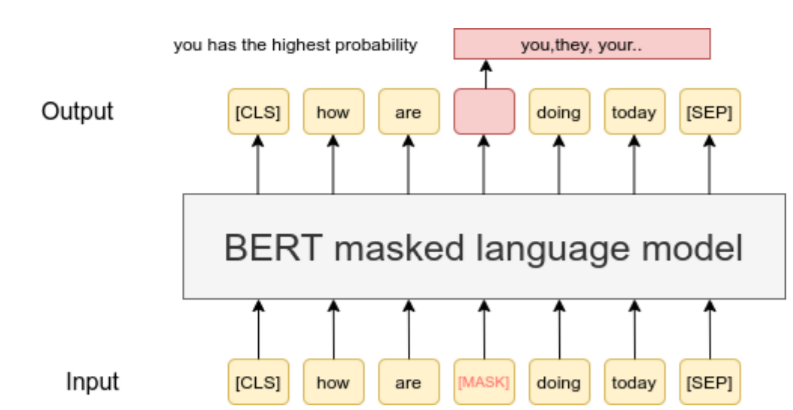 Cara Kerja BERTBERT dibangun di atas arsitektur encoder Transformer. BERT menggunakan tumpukan lapisan self-attention yang memungkinkan setiap kata dalam kalimat untuk berinteraksi dengan setiap kata lainnya. Konteks BidirectionalInovasi terpenting BERT adalah pendekatan pelatihan dua arahnya. Bukan memprediksi kata berikutnya dalam sebuah urutan, BERT menggunakan teknik pelatihan yang disebut Masked Language Modeling (MLM). Selama pelatihan, kata-kata tertentu dalam kalimat disembunyikan (dimasker), dan model harus memprediksinya berdasarkan kata-kata di sekitarnya. Karena memiliki akses ke konteks kiri dan kanan, BERT mempelajari hubungan semantik yang lebih dalam. Layer Transformer EncoderBERT menggunakan beberapa layer encoder Transformer, masing-masing berisi mekanisme self-attention dan neural network feed-forward. Layer-layer ini memproses embedding input dan menyempurnakan makna kontekstualnya di setiap tahap. Mekanisme self-attention memberikan bobot yang berbeda kepada kata-kata yang berbeda dalam kalimat, tergantung pada seberapa relevan kata-kata tersebut satu sama lain. Hal ini memungkinkan model untuk menangkap hubungan halus seperti tata bahasa, nada, dan makna semantik. 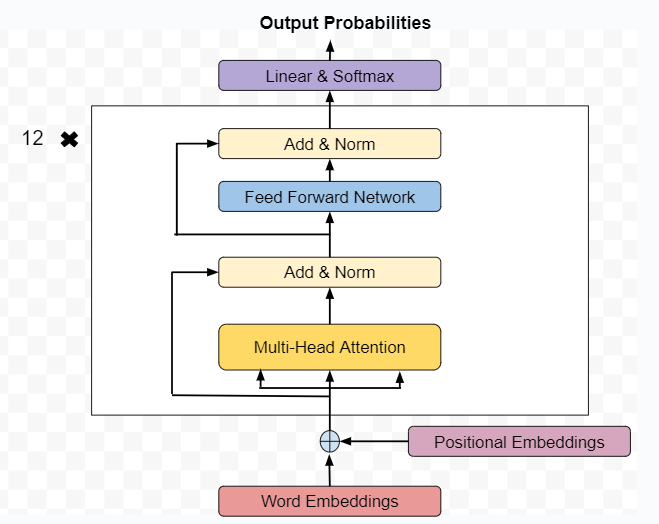 Pre-Training dan Fine-TuningKeberhasilan BERT berasal dari proses pelatihan dua tahapnya, yaitu pre-training dan fine-tuning. Selama pre-training, BERT dilatih pada korpus teks besar untuk mempelajari pola bahasa umum. Ia mempelajari tata bahasa, struktur kalimat, dan hubungan kontekstual tanpa dilatih untuk tugas spesifik. Setelah pre-training, BERT dapat disesuaikan (fine-tuning) untuk aplikasi spesifik seperti analisis sentimen, menjawab pertanyaan, atau pengenalan entitas bernama. Fine-tuning membutuhkan data dan daya komputasi yang jauh lebih sedikit dibandingkan dengan pelatihan dari awal. Pendekatan pembelajaran transfer ini membuat BERT sangat mudah beradaptasi dan efisien. Aplikasi BERTBERT banyak digunakan di berbagai industri karena kemampuan pemahaman bahasanya yang kuat. Dalam mesin pencari, BERT membantu menafsirkan kueri pengguna dengan lebih akurat dengan memahami bahasa alami daripada mencocokkan kata kunci. Misalnya, Google mengintegrasikan BERT ke dalam algoritma pencariannya untuk menafsirkan kueri percakapan dengan lebih baik. Dalam chatbot dan asisten virtual, BERT meningkatkan kemampuan sistem untuk memahami maksud dan konteks pengguna. Dalam analisis sentimen, BERT dapat mendeteksi emosi yang bernuansa dalam teks. Dalam sistem tanya jawab, BERT dapat mengekstrak jawaban yang tepat dari dokumen yang besar. BERT juga digunakan dalam analisis dokumen hukum, interpretasi rekam medis, dan pemrosesan teks keuangan. Perbedaan BERT dengan Model Bahasa LainnyaDibandingkan dengan model-model sebelumnya seperti Word2Vec atau GloVe, BERT menghasilkan embedding kata yang kontekstual. Ini berarti bahwa kata yang sama dapat memiliki representasi yang berbeda tergantung pada konteksnya. Tidak seperti model autoregresif yang menghasilkan teks secara berurutan, BERT dirancang terutama untuk pemahaman daripada generasi. Model-model selanjutnya, seperti GPT, lebih fokus pada kemampuan generatif. Namun, kedua jenis model tersebut bergantung pada arsitektur Transformer yang diperkenalkan pada tahun 2017. Kekurangan BERTTerlepas dari kelebihannya, BERT memiliki beberapa kekurangan. Pertama, dibutuhkan sumber daya komputasi yang substansial untuk pre-training. Model BERT yang besar mengandung ratusan juta parameter. Kedua, meskipun BERT unggul dalam tugas pemahaman, ia tidak dioptimalkan untuk generasi teks. Lebih cocok untuk tugas klasifikasi, ekstraksi, dan interpretasi. Selain itu, seperti model AI lainnya, BERT mungkin mewarisi bias yang ada dalam data pelatihannya, yang terus ditangani oleh para peneliti. Varian dan Peningkatan BERTSejak dirilis, banyak varian BERT telah dikembangkan untuk meningkatkan efisiensi dan kinerja. Model seperti RoBERTa, DistilBERT, dan ALBERT menyempurnakan metode pelatihan, mengurangi ukuran model, atau meningkatkan kinerja pada benchmark tertentu. Peningkatan ini bertujuan untuk membuat model berbasis Transformer lebih cepat, lebih efisien, dan lebih mudah diakses sambil mempertahankan kemampuan pemahaman bahasa yang kuat. Mengapa BERT Penting Saat IniBERT mentransformasi NLP dengan menunjukkan kekuatan konteks dua arah dan pembelajaran transfer. Pengaruhnya meluas jauh melampaui rilis aslinya, sehingga menginspirasi seluruh generasi model berbasis Transformer. Saat ini, sebagian besar sistem NLP modern dibangun di atas prinsip-prinsip yang diperkenalkan oleh BERT. Ini telah menjadi model dasar dalam penelitian AI dan aplikasi dunia nyata. Memahami BERT akan memberikan wawasan tentang bagaimana mesin menafsirkan bahasa manusia dengan semakin canggih. Advertisement:
Jadi, BERT (Bidirectional Encoder Representations from Transformers) adalah model deep learning yang merevolusi pemrosesan bahasa alami dengan memungkinkan pemahaman konteks dua arah. Dibangun di atas arsitektur encoder Transformer, BERT unggul dalam tugas pemahaman bahasa seperti pencarian, analisis sentimen, dan menjawab pertanyaan.
Dengan menggabungkan pelatihan awal skala besar dengan penyempurnaan khusus tugas, BERT menetapkan standar baru untuk pemahaman bahasa AI dan terus memengaruhi pengembangan AI modern. Artikel Terkait:
|